An idempotent function gives the same result even if it is applied several times. That is exactly how a database update script should behave. It shouldn’t matter if it is run on or multiple times. The result should be the same. A database update script should be made to first check the state of the… Continue reading Idempotent DB Update Scripts
Category: SQL
Always Check Generated SQL
OR-Mappers are great for making data access easier, but they are not an excuse for learning SQL. As an application developer, I’m responsible for all the SQL queries issued by the application. If I use an ORM, it’s my responsibility to check the generated SQL. I’ve already written another post named Always Check Generated SQL… Continue reading Always Check Generated SQL
Update-Database MSI Custom Action
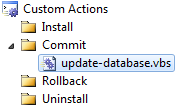
In the Prevent EF Migrations from Creating or Changing the Database post I showed how to prevent the application from automatically creating or updating the database. Instead I want the installation program to do that. With a Web Setup Project for the installation an MSI Custom Action is needed. The actual work of updating the database is done… Continue reading Update-Database MSI Custom Action
Database Table Primary Keys
When designing a database, I have a standard of always creating a clustered primary key in each table of type INT IDENTITY(1,1) NOT NULL. CREATE TABLE Cars( ID INT IDENTITY(1,1) NOT NULL CONSTRAINT PK_Cars PRIMARY KEY CLUSTERED, Brand NVARCHAR(20) NOT NULL, RegistrationNumber NVARCHAR(10) NOT NULL, MadeIn NVARCHAR(20) NOT NULL )CREATE TABLE Cars( ID INT IDENTITY(1,1)… Continue reading Database Table Primary Keys
Transaction Safety for Manual SQL Updates
When maintaining a system that is in production there are often issues that need to be solved by running custom SQL scripts directly in the production database. There can be different reasons for this: Updating a lookup table to add a new option to dropdown boxes, where there is no user interface for handling the… Continue reading Transaction Safety for Manual SQL Updates