I’m a fan of code coverage as a way to ensure that there are covering tests. One area that I tend to rely heavily on Code Coverage for is to catch any tests that are no longer working correctly due to changes in the production code. That often works out well, but today I got… Continue reading When Code Coverage Betrayed Me
Tag: Unit Tests
Code Coverage does Matter
Is it relevant to have a code coverage target? In a talk at NDC Oslo 2014 Uncle Bob said that the only reasonable goal is 100%. On the other hand Mark Seemann recently said on twitter and in a follow up blog post that “I thought it was common knowledge that nothing good comes from… Continue reading Code Coverage does Matter
Regression Testing Processing Algorithms
This is a guest post by Albin Sunnanbo sharing experiences on regression testing. On several occasions I have worked with systems that processed lots of work items with a fairly complicated algorithm. When doing a larger rewrite of such an algorithm you want to regression test your algorithm. Of course you have a bunch of… Continue reading Regression Testing Processing Algorithms
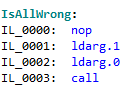
Code Coverage != Functional Coverage
To reach 100% testing coverage is a dream for many teams. The metric used is code coverage for tests, but is that enough? Unfortunately not. Code line coverage is not the same as functional coverage. And it is full functional coverage that really matters in the end. Look at a simple method that formats a… Continue reading Code Coverage != Functional Coverage
Rerunning all Unit Tests with Different UI Culture
I was recently made aware that some unit tests for Kentor.AuthServices were failing on non-English computers. To handle that, I set up an Azure VM with Swedish installed and made a special unit test that would run all other tests with different UI cultures. When I first understood that I had tests that were broken… Continue reading Rerunning all Unit Tests with Different UI Culture